

选自
机器之心合辑
参与:赵化龙、邵明、吴盼、李泽南
在使用深度神经网络进行预测之前,您首先必须训练神经网络。 存在许多用于训练神经网络的不同工具,并且正在迅速成为其中最受欢迎的选择。 近日,一位独立开发者在自己的博客上发布了关于如何在iOS系统上运行的深度长文教程,并开源了相关代码。 机器之心本文整理介绍。 有关更多信息和教程,请参阅机器之心文章“”和“”。
项目地址:
您可以使用它来训练您的机器学习模型并使用这些模型进行预测。 训练通常在强大的机器或云端完成,但也可以在 iOS 上运行——尽管有一些限制。
在这篇博文中,我将解释它背后的想法,如何使用它来训练一个简单的分类器,以及如何将这个分类器放入您的 iOS 应用程序中。
我们将学习如何使用用于音频和语音分析的性别识别数据集(通过 Voice 和 , )将录音识别为男声或女声。 你可以在上面的地址找到这个项目的源代码。
它是什么以及为什么我需要它?
是一个为机器学习构建计算图(图)的软件库。
许多其他工具在更高的抽象级别上工作。 以 Caffe 为例,您可以通过连接不同类型的“层”来设计神经网络。 这类似于 BNNS 和 iOS 的功能。 在 中,您也可以使用此类层,但您可以更深入地研究构成算法的各个计算。
您可以将其视为实现新机器学习算法的工具包,而其他深度学习工具则用于使用其他人实现的算法。
这并不意味着您总是必须从头开始构建所有内容。 附带了一组可重用的构建块,还有其他库(例如 Keras)也在其上提供了方便的模块。
所以精通数学不是使用的要求,但如果你想成为顶级专家就应该是。
基于回归的二元分类
在这篇博文中,我们将使用回归算法创建一个分类器。 是的,我们将从头开始构建它。 那就撸起袖子开始吧!
分类器获取一些输入数据并告诉您该数据属于哪个类别或类别。 对于这个项目,我们只有两个类别:男性或女性,所以我们是一个二元分类器 ( )。
注意:二元分类器是最简单的分类器,但它使用了与可以区分数百或数千个不同类的分类器相同的思想。 因此,即使我们在本教程中并没有真正进行深度学习,两者仍然有很多共同点。
我们将使用的输入数据由 20 个数字组成,代表某人说话的特定录音的各种声学特性。 我稍后会解释,包括音频频率等信息。
在下图中,您可以看到这 20 个数字连接到一个名为 sum 的小块。 根据分类器的不同,这些连接具有不同的权重 ( ),对应于这 20 个数字中每个数字的重要性。
这是分类器如何工作的框图:
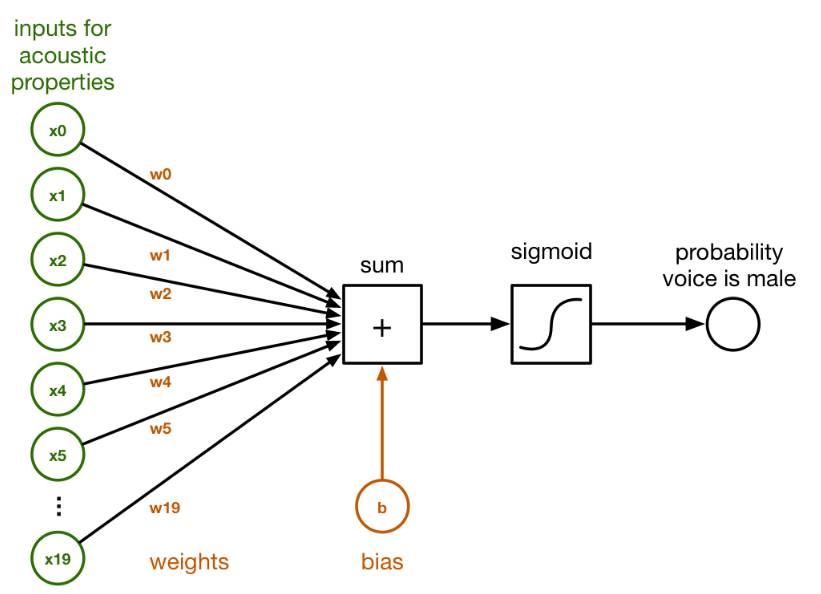
在求和块内部,由 x0 - x19 给出的输入及其连接权重 w0 - w19 简单地加在一起。 这是一个普通的点积:
我们还在最后添加了一个所谓的偏置项 b。 这只是另一个数字。
数组中权重w和b的值就是这个分类器要学习的东西。 训练分类器就是找到 w 和 b 的正确数字。 最初,我们将所有 w 和 b 设置为零。 经过多轮训练后,w 和 b 将包含一组数字,分类器可以使用这些数字来区分男性和女性的语音。
要将此总和值转换为介于 0 和 1 之间的概率值,我们使用以下函数:
这个公式可能看起来很吓人,但它的作用很简单:如果 sum 是一个大的正数,函数返回 1,表示 100% 的概率。 如果 sum 是一个大的负数,函数返回 0。因此对于大的正数或负数,我们可以得到一个有把握的“是”或“否”预测。
但是,如果 sum 接近 0,该函数给出的概率接近 50%,因为它对预测没有信心。 当我们开始训练这个分类器时,初始预测将被分成两半,因为分类器还没有学到任何东西并且对结果没有信心。 但是我们训练得越多,概率越倾向于 1 和 0,分类器就变得越具体。
现在,包含预测,其概率是语音来自男性的概率。 即,如果超过 0.5(或 50%),我们认为声音是男性,否则是女性。
这就是使用回归的二元分类的思想。 分类器的输入由 20 个描述录音声学特性的数字组成,我们计算加权和并取函数,我们得到的输出是说话者是男性的概率。
然而,我们仍然需要建立机制来训练这个分类器,所以让我们现在看一下。
实现分类器
要在 中使用这个分类器,我们首先需要将其设计转换为计算图。 计算图由执行计算的节点和在这些节点之间流动的数据组成。
我们的回归图如下所示:
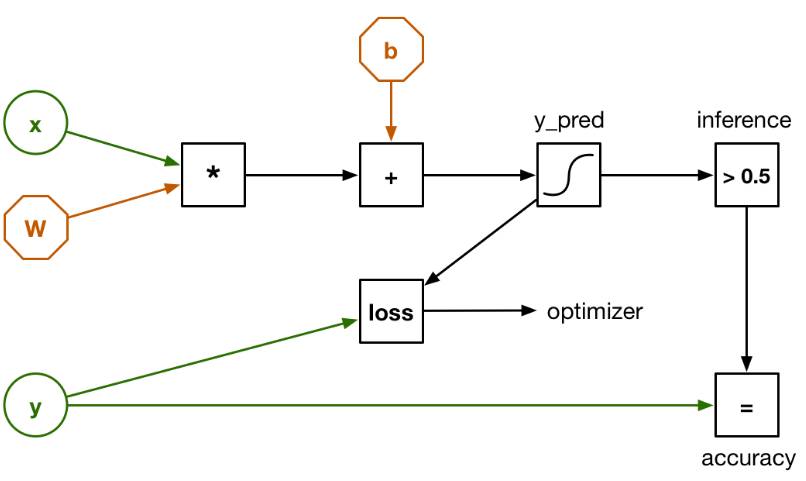
这看起来与之前的图表有点不同,但那是因为输入 x 不再是 20 个单独的数字,而是一个包含 20 个元素的向量。 权重由矩阵 W 表示。因此,之前的点积由单个矩阵乘法代替。
还有一个输入 y。 这用于训练分类器并验证其有效性。 我们使用的数据集有 3,168 个记录样本,我们也知道每个样本是男性还是女性。 那些已知的结果(男性或女性)也被称为数据集的标签,这就是我们将放在 y 中的内容。
为了训练这个分类器,我们将其中一个样本加载到 x 中,让图表做出预测:它是男性还是女性? 因为初始权重全为零,分类器可能会做出错误的预测。 我们需要一种方法来计算误差程度——通过损失函数(loss)。 损失函数将预测结果与正确结果 y 进行比较。
在确定训练样本的损失后,我们使用一种称为反向传播()的技术通过计算图向后工作,以在正确的方向上调整权重 W 和 b。 如果预测是男性,但正确答案是女性,则权重会上下移动一点,以便下一次“女性”更有可能是该特定输入的结果。
这个训练过程在数据集的所有样本上一遍又一遍地重复,直到图形确定最佳权重集。 随着时间的推移,用于衡量预测误差的损失变得越来越低。
反向传播是训练此类图的一种很好的技术,但所涉及的数学可能有点棘手。 这是很酷的部分:由于我们将所有“前向”操作表示为图中的节点,它可以自动计算出反向传播的“后向”操作——你不必自己做任何数学运算,这太棒了!
那么什么是张量呢?
在上图中,数据从左到右流动,从输入到输出。 这是名称的“流”部分。 但是什么是张量()?
流经图形的所有数据都以张量的形式存在。 张量只是 n 维数组的一个很酷的名字。 我说了W是权重矩阵,但是从术语上来说,它其实是一个二阶张量(-order)——换句话说,就是一个二维数组。
这就是所有要说的。 在卷积神经网络等深度学习方法中,你通常处理四维张量,但我们的分类器要简单得多,所以我们不会超越二阶张量或矩阵。
我还说过 x 是一个向量——或者更确切地说是一个 1 阶张量——但我们将把它当作一个矩阵。 y 也是如此。 这使我们能够一次计算整个数据集的损失。
单个样本有 20 个数据元素。 如果我们将所有 3,168 个样本加载到 x 中,那么 x 将变成一个 3168×20 的矩阵。 x 和 W 相乘后,结果是一个 3168×1 的矩阵。 也就是说,数据集中的每个样本都有一个预测。
通过将我们的图表示为矩阵/张量,我们可以一次对许多样本案例进行预测。
安装
好的,理论结束。 现在让我们付诸实践。 我们将使用 with 。 您的 Mac 可能已经安装了一个版本,但它可能是旧版本。 我在本教程中使用 3.6,因此最好也安装它。
使用包管理器安装 3.6 是最简单的。 如果您尚未安装该软件,请先按照以下说明进行操作:
然后打开一个终端并输入以下命令来安装最新版本:
带有自己的包管理器 pip,我们将使用它来安装我们需要的包。 从终端执行以下操作:

此外,我们将安装 NumPy、SciPy 和 -learn:
您不一定需要使用和学习,但它们很方便,可以在任何数据科学家的工具箱中找到。
这些软件包将安装在 /usr/local/lib/.6/site- 中。 如果您需要查看源代码并且网站上没有相关文档,这将非常有用。
注意:pip 会自动为您的系统安装最佳版本。 如果要安装其他版本,请参考官方安装说明()。 您也可以从源代码编译,我们稍后会在为 iOS 构建时进行一些编译。
让我们做一个快速测试,以确保一切都正确安装。 使用以下内容创建一个新的文本文件 tryit.py:
然后从终端运行这个脚本:
它会输出一些关于它正在运行的设备的调试信息(很可能是 CPU,但也可能是 GPU - 如果你的 Mac 有 GPU)。 最后它应该输出,
这是两个向量 a 和 b 的总和。
您可能还会看到以下消息:
如果发生这种情况,您系统上安装的版本不是您 CPU 的最佳选择。 解决此问题的一种方法是从源代码编译: ,因为这样您就可以配置所有选项。 但到目前为止,如果您看到这些警告,那没什么大不了的。
仔细看数据
要训练分类器,您需要数据。
对于这个项目,我们使用了 Kory 的“by Voice”数据集,这是我在网站上找到的。
下载链接:
那么如何从音频中识别语音呢? 如果您下载数据集并查看 voice.csv 文件,您只会看到一行又一行的数字:

重要的是要意识到这不是实际的音频数据! 相反,这些数字代表音频的不同声学特性。 这些属性(或特征)通过脚本从音频中提取并转换为此 CSV 文件。 这个过程的解释超出了本教程的范围,但如果您有兴趣,可以参考原始的 R 语言源代码:
该数据集包含 3,168 个这样的样本(表中每一行一个),大约一半是男性说话者,一半是女性说话者。 每个样本有 20 个声学特征,例如:
对于其中的大多数,我不知道它们是什么意思,也不是很重要。 我们关心的是,我们可以使用这些数据来训练一个分类器,根据这些特征来区分男性和女性的声音。
如果你想在你的应用程序中使用这个分类器来判断麦克风音频或录音中说话者的性别,你首先必须从音频数据中提取这些声学属性。 一旦你有了这 20 个值,你就可以将它们提供给训练有素的分类器,它会告诉你声音是男性还是女性。 所以我们的分类器不会直接在录音上工作,而只会在从录音中提取的特征上工作。
注意:这是指出深度学习和更传统的算法(如回归)之间区别的好地方。 我们正在训练的分类器无法学习非常复杂的东西,您需要通过在预处理步骤中从数据中提取特征来帮助它。 对于这个特定的数据集,它是从音频中提取声学特征。
深度学习的妙处在于,你可以训练一个神经网络来学习如何自行提取这些声学特征。 因此,深度学习系统可以将原始音频作为输入,提取它认为重要的声学特征,然后在不进行任何预处理的情况下对其进行分类。
创建训练和测试集
早些时候我提到我们通过以下方式训练分类器:
1. 为它提供数据集中的所有样本
2. 衡量预测的错误程度
3.根据loss调整权重
实际上我们不应该将所有数据都用于训练。 我们需要分离出一部分数据(称为测试集),以便我们可以评估分类器的性能。 因此,我们将数据集分为两部分:用于训练分类器的训练集和用于查看分类器准确性的测试集。
为了将数据拆分为训练集和测试集,我创建了一个名为 .py 的脚本:
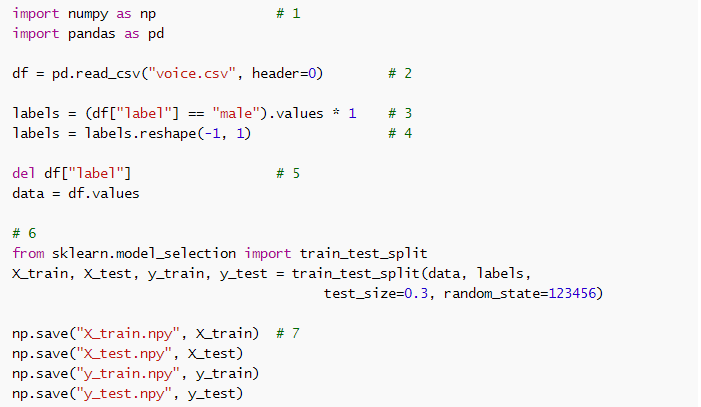
一步一步,这个脚本是这样工作的:
导入 NumPy 和包。 允许我们轻松加载 CSV 文件并预处理数据。
使用 将数据集从 voice.csv 加载到 中。 该对象的工作方式很像电子表格或 SQL 表。
标签列包含数据集的标签:样本是男性还是女性。 在这里,我们将标签提取到一个新的 NumPy 数组中。 原始标签是文本,但我们将它们转换为数字:1=男性,0=女性。 (这些数字的分配是任意的——在二元分类器中,我们经常使用 1 来表示“正”类,或者我们试图检测的类)。
这个新数组是一个一维数组,但我们的脚本将有一个 3,168 行的二维张量,每行一列。 所以在这里我们将该数组“重塑”为二维。 这不会改变内存中的数据,只是 NumPy 从现在开始解释它的方式。
一旦我们完成了标签列,我们将其删除,所以我们剩下 20 个描述输入的特征。 我们还将其转换为常规 NumPy 数组。
我们使用 -learn 的辅助函数将数据和数组分成两部分。 这会根据 随机重新排列数据集中的样本,这是随机生成器的种子。 这个种子是什么并不重要,但如果我们总是使用相同的种子,我们就可以创建一个可重复的实验。
最后,将四个新数组保存为 NumPy 的二进制文件格式。 我们现在有一个训练集和一个测试集!
您可以在此脚本中对数据进行其他预处理(例如扩展功能)以获得零均值和相等方差; 但我没有将它包含在这个简单的项目中。
从终端运行以下脚本:
这为我们提供了四个新文件,其中包含训练样本 (.npy) 及其标签 (.npy) 和测试样本 (.npy) 及其标签 (.npy)。
注意:您可能想知道为什么有些变量名是大写的,而另一些则不是。 在数学中,矩阵通常用大写字母书写,向量通常用小写字母书写。 在我们的脚本中,X 是矩阵,y 是向量。 这样的约定在很多机器学习代码中很常见。
构建计算图
现在我们已经组织好数据,可以编写脚本来训练分类器了。 这个脚本叫做 train.py。 为了节省篇幅,我不会在这里展示整个脚本,你可以在这里看到。
同样,我们从导入我们需要的包开始。 然后我们将训练数据加载到两个 NumPy 数组中: 和 。 (我们不会在此脚本中使用测试数据。)

现在我们可以创建我们的计算图。 首先,我们为输入 x 和 y 定义所谓的 ():

tf.("...") 可用于将图的不同部分分组到不同的范围内,这样更容易理解图。 我们将 x 和 y 放在“输入”范围内。 我们还将它们命名为“x-input”和“y-input”,以便我们以后可以轻松地引用它们。
回想一下,每个输入样本都是一个 20 元素向量。 每个样本也有一个标签(1 是男性,0 是女性)。 我也提到如果我们把所有的样本合并成一个矩阵,我们可以一次性计算出所有的数据。 这就是为什么这里将 x 和 y 定义为二维张量:x 的维度为 [None, 20],y 的维度为 [None, 1]。
None 表示第一个维度是灵活的且未知。 对于训练集,我们将在 x 和 y 中放置 2,217 个样本; 对于测试集,951 个样本。
现在,知道我们的输入是什么,我们可以定义分类器()的参数:
张量 W 包含分类器将学习的权重(一个 20×1 矩阵,因为有 20 个输入特征和 1 个输出),b 包含偏置值。 这两个被声明为变量,这意味着它们可以通过反向传播过程进行更新。
准备就绪后,我们可以在回归分类器的核心声明计算:
其中 x 和 W 相乘,加上偏置 b,然后执行。 结果就是x中的特征所描述的音频数据的说话人是男性的概率。
注意:上面的代码行实际上并没有计算任何东西——我们所做的只是创建一个计算图。 这行代码只是简单地向图中添加节点以进行矩阵乘法 (tf.)、加法 (+) 和函数 (tf.)。 一旦我们构建了整个图表,我们就可以创建一个会话并在实际数据上运行它。
我们还没有完成。 为了训练模型,我们需要定义一个损失函数(loss)。 对于二元回归分类器,使用对数损失是有意义的,幸运的是有一个内置的()函数可以让我们免于编写实际的数学:
图节点将 y(我们当前正在查看的样本的标签)作为输入,并将它们与我们的预测进行比较。 这会产生一个代表损失的数字。
当我们开始训练时,对于所有样本,预测将为 0.5(即 50% 的男性概率),因为分类器不知道正确答案应该是什么。 因此,用-ln(0.5)计算的初始loss为0,随着训练的进行,loss会越来越小。
计算损失的第二行添加了称为 L2 正则化 (L2) 的东西。 这样做是为了防止过度拟合,使分类器无法准确记住训练数据。 在这里,这不会是一个大问题,因为我们的分类器的“记忆”只包含 20 个权重值和一个偏置值。 但正则化是一种常见的机器学习技术,所以我想我会把它包括在内。
值是另一个占位符:
我们使用占位符来定义输入 x 和 y,但它们也可用于定义超参数 ( )。 超参数允许您配置模型及其训练方式。 它们被称为“超”参数,因为与常规参数 W 和 b 不同,它们不是由模型学习的——你必须自己将它们设置为适当的值。
(学习率)超参数告诉优化器它应该采取多大的步骤。 () 是执行反向传播的:它将损失作为输入并将其反馈到图中以确定更新权重和偏差的程度。 有很多可能的优化器,我们将使用 ADAM:
这将在图中创建一个名为 的节点。 这是我们稍后将运行以训练分类器的节点。
为了确定分类器的表现如何,我们将在训练期间偶尔拍摄快照并计算训练集中已被正确预测的示例数量。 训练集上的准确率并不能很好地指示分类器的表现如何,但无论如何它对跟踪训练很有用——如果你正在训练并且训练集上的预测准确率变差,那一定是哪里出了问题!
我们定义一个图形节点来计算精度:
我们可以运行该节点以查看正确预测了多少样本。 回想一下,它包含 0 到 1 之间的概率。通过执行 tf.(>0.5),如果预测是女性,我们得到的值为 0,如果预测是男性,我们得到的值为 1。 我们可以将它与包含正确值的 y 进行比较。 准确性就是正确预测的数量除以预测总数。
稍后,我们还将在测试集上使用相同的节点来查看分类器的实际性能。
多定义一个节点很有用。 这个节点用于对我们根本没有任何标签的数据进行预测:
要在您的应用程序中使用此分类器,您需要记录一些话语,对其进行分析以提取 20 个声学特征,并将其提供给分类器。 由于这是新数据,而不是来自训练或测试集的数据,显然不会有标签。 您只能将这些新数据提供给分类器,并希望它预测出正确的结果。 这是(推理)节点需要做的。
好的,在创建计算图之前做了很多工作。 现在我们想在训练集上实际训练它。
训练分类器
训练通常是一个无限循环的过程。 训练一个简单的、稍微强大一点的回归分类器,通常可以在一分钟内完成,但如果要训练一个性能优异的深度神经网络,则可能需要数小时甚至数天才能完成。
这是“train.py”文件中训练循环的第一部分:

首先,我们在 中创建一个新对象。 为了运行计算图,您需要先启动 ()。 调用 sess.run(init) 将 W 和 b 重置为 0。
我们还将此计算图写入文件。 将我们刚刚创建的所有节点序列化到文件 /tmp/voice/graph.pb 中,我们稍后在测试集上运行分类器时需要这个定义图,我们也可以将这个训练好的分类器放入 iOS 应用程序中。
在这个 while True 中,我们执行以下命令:
首先,我们打乱训练样本——这一步很重要,因为您不希望分类器无意中了解样本的顺序。
下一点很重要:我们告诉节点运行,它将在计算图上执行一次训练。
当你运行sess.run()时,你需要提供一个,就是告诉你要()节点中对应的输入数据。
由于这是一个非常简单的分类器,我们总是一次训练整个训练集。 我们将 , 的训练数据分别传入占位符 x, y。 对于更大的数据集,可以使用batch训练的方式,比如每batch训练100-1000个样本。
这些都是我们需要做的。 训练是一个循环过程,所以节点会运行很多很多次。 在每次迭代中,反向传播机制会对权重 W 和 b 进行微小的更改。 经过多次训练,我们一般可以得到最优或更好的权重值。
了解训练过程对我们理解神经网络很有帮助,所以我们打印出训练过程的进度报告(在本项目中,每1000步打印一次):

这次,我们没有运行节点,而是有其他节点:() 和损失函数(loss)。 我们使用相同的方法来计算训练集的准确性和损失函数。
正如我之前所说,在训练集上表现良好的分类器不一定在测试集上表现良好。 但是有一点是可以肯定的,就是你很想看到准确率随着训练不断上升,而损失函数值不断下降。
很多时候我们保存一个()。
将分类器学习到的W和b的值保存到一个文件中,当我们要在测试集上运行分类器时,我们会再次从文件中读取数据。 文件保存在 /tmp/voice/ 目录中。
在终端中输入以下命令运行训练脚本:
输出应该是这样的:
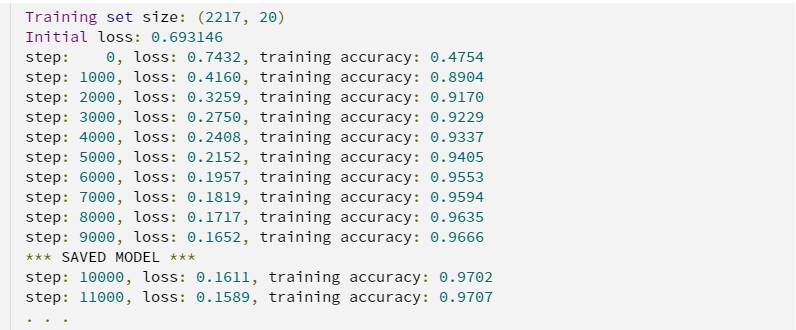
一旦看到损失函数停止下降,等到看到消息*** SAVED MODEL ***,然后在电脑上按Ctrl+C停止训练。 使用我选择的正则化参数和学习率,你应该看到训练集上的准确率约为 97%,损失函数约为 0.157(如果你将正则化参数设置为 0,损失函数值会更小)。
分类器的表现如何?
训练完分类器后,我们需要测试它在现实生活中的表现。 然后,您需要在未用于训练的数据上评估分类器,这就是我们将数据集拆分为训练集和测试集的原因。
我们新建了一个脚本test.py来加载定义好的计算图和测试集,最后计算测试集中的分类准确率。
注意:测试准确率总是低于训练准确率(本文为 97%),但不会差很多。 如果你的分类器在测试集上的准确率远低于在训练集上的准确率,那么你的分类器很可能过度拟合,你需要重新调整你的训练过程。 我们希望这个分类器在测试集上的准确率为 95%,如果低于 90%,则需要引起注意。
和以前一样,相关包首先在脚本中导入。 包括使用-learn中的包打印一些相关的报告。 当然,这次我们加载的是测试集而不是训练集。

为了在测试集上计算准确率,我们需要再次使用我们的计算图,但这不是使用整个计算图,这里我们不需要使用和损失节点。
我们可以再次手动构建此图,但由于我们已经将其保存在 graph.pb 文件中,因此我们只需要加载它。 代码如下:

喜欢将其数据存储为 文件(扩展名为 .pb),因此我们使用一些辅助代码来加载该文件并将其作为图形导入到会话中。
接下来,我们需要从文件中加载训练好的W和b值:

这就是为什么我们限定节点的范围并给它们相应的名称,这样我们就可以使用 () 函数轻松地再次找到它们。 如果你不给你的节点有意义的名字。 那么你将很难找到它们。
我们还需要获取某些节点的 (),特别是输入 x、y 和进行预测的节点。

OK,至此,我们已经将计算图加载到内存中了。 我们还加载了之前分类器训练的 W 和 b。 现在我们可以在测试集(以前看不见的数据集)上进行测试。
使用make ,将预测值与标签进行比较,验证预测是否准确,并计算准确率。
注意:这次在 中,不需要指定正则化参数和学习率。 我们只需要运行计算图中的相关部分,不需要使用计算图中的占位符部分。 我们还可以使用 -learn 包生成一些其他报告:

这次我们使用节点来进行预测。 由于只计算预测值,不检查预测值的准确性,所以只需要传入x(不需要y)。
运行此脚本,您应该会看到类似于以下内容的输出:
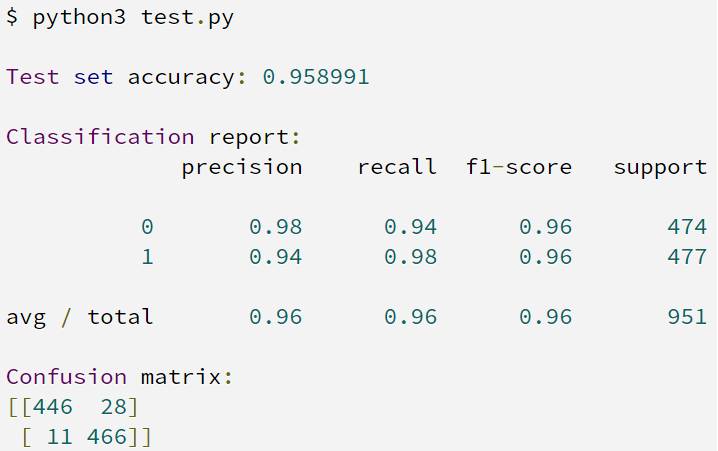
测试集上的准确率接近 96%,正如预期的那样,测试集上的准确率低于训练集上的准确率。 这意味着我们的训练非常成功,我们的模型在看不见的数据上也成功运行。 它并不完美:几乎每 25 个预测中就有 1 个是错误的。 但就我们的目的而言,这很好。
分类报告和混淆矩阵显示错误预测示例的统计数据。 从混淆矩阵中,446名女性被正确预测,28名女性被误判为男性; 正确预测男性466人,误判女性11人。
似乎分类器在预测女性时更容易出错,分类报告的准确率/召回率也显示了同样的事实。
基于 iOS 构建
现在我们已经训练了一个在测试集上表现良好的模型,让我们构建一个简单的 iOS 应用程序来根据模型进行预测。 首先,我们将创建一个使用 C++ 库的应用程序。 在下一节中,我们将在 Metal 中使用此模型进行比较。
当然,这样做有利也有弊。 坏消息是您必须从源代码构建。 实际上,情况变得更糟:您需要安装 Java 才能执行此操作。 好消息是这个过程相对简单。 可以在这里找到完整的说明(Full are here ()),但需要以下步骤(在 1.0 上测试)。
当然,你应该已经安装了Xcode,并确保激活指向的是Xcode安装的目录(如果你之前安装过Xcode,这可能指向错误的位置,这样会安装不成功。)
To build, you need to use a tool bazel, and bazel Java JDK 8 . It's easy to the you need with:
Once you have the above steps, you need to clone the . Note: save this in a path , bazel will to build! I clone this into my home :
The -b r1.0 means to clone the r1.0 . Of , you are also free to grab the or main at any time.
NOTE: On macOS, the below will give some . I had to clone the . On OS X El, the r1.0 has no .
After the step, you need to run the .
Here are some you may , and I give their here:
the , the path is /usr/bin/. Since I want to use the .6 , the path be /usr/local/bin/. If you the , it will be built on top of .7.
the to be used , the is -march=.
只需按下回车确认即可。接下来的几个问题选择「n」代替「no」即可。
当他询问要使用哪个库的时候,请按下Enter 选择默认选项(这应该是.6 库)。
剩下的几个问题用「n」代替「no」来回答即可。现在脚本将下载一些依赖并为建立做准备。
建立静态库
构建有如下两个选项:
1. 在Mac 上,使用bazel 工具
2. 在iOS 上,使用
我们想为iOS 构建,所以我们使用第二个选项。然而,我们也将需要构建一些与选项一有关的额外工具。
在的目录下中执行以下脚本:
首先下载几个依赖,然后启动构建程序。如果一切都顺利的话,它将创建三个需要链接到你应用程序的静态库:-core.a,.a,-lite.a。
警告:建立这些库需要花费一段时间:在我的iMac 上,用了将近20 多分钟,在相对较老的Pro 上,则花费了超过3 个小时。在安装过程中,你也可能会看到很多编译警告信息,甚至错误信息。最简单的处理方式:先忽略它们。
现在,我们还需要另外另个辅助安装工具。在终端运行下面两条命令:
注意:这将需要花费20 分钟左右的时间,因为它是从头开始构建(此次使用bazel);如果此过程中遇到麻烦,请参阅官方说明。
为Mac 构建
这一步是可选项,但是由于你已经安装好了所有依赖环境,所以要为你的Mac 建立一点儿也不困难。这创建了一个新的pip 包,因此你不需要利用官方包进行安装。
Why do you want to do this?因为这样你就可以创建一个具有自定义选项的版本。例如,当你在运行train.py 文件时,如果你得到「The wasn't to use SSE4.1 」的警告信息时,你可以编译一个能执行这些指令的版本。
要为Mac 构建,在终端运行运行下面的命令:
「-march= 」选项对SSE, AVX, AVX2, FMA 等指令(如果这些指令能够在你的CPU 上可用的话)增加了支持。
然后安装下面的包:
更多详细说明,请参考官网。
图
我们将建立的iOS 应用程序将加载我们曾经训练好的模型,并用此应用程序来做一些预测。
回忆一下,train.py 文件将计算图的定义保存到了/tmp/voice/graph.pb 之中。很遗憾的是,你不能将此图原样地加载到iOS 应用程序中。完整的计算图包含某些不受C++ API 的支持的操作。这就是为什么我们需要使用两个额外工具的原因。
能将graph.pb 文件和保存模型训练好的超参数值W 和b 的文件合并到一个文件中,它还能够移除iOS 不支持的任何操作。
在终端的的目录下运行此工具:

这就在/tmp/voice/.pb 文件中创建了一个简化图,其中只包含到和的所有结点,它不包括用于训练的结点。
使用的优势在于它能够将训练好的权重粘贴到文件中,所以你不需要单独加载它们: .pb 包含了我们所需要的一切内容。
ce 工具将进一步简化图,它将.pb 文件作为输入,写入/tmp/voice/.pb 文件作为输出。这个输出文件就是我们将要嵌入在iOS 应用程序中的文件,使用如下命令运行此工具。

iOS应用程序
你可以在文件夹中的//-iOS- 中找到该iOS 应用程序.
在Xcode 中打开项目,你需要注意如下几点:
转到项目设置屏幕并切换到构建设置选项卡。在其他链接器标识符下,你将看到以下内容:

除非你的命名也是「」,否则你将需要用克隆的仓库路径来代替它。(注意出现两次,因此文件夹名称应该为/ / ...)
注意:你也可以将这三个.a 文件复制到项目文件夹中,然后你就不需要担心路径出错的问题了。对于这个项目我不想这样做,因为-core.a 太大,是一个占用440MB 的库。
然后检查标题搜索路径(** Paths**),它们当前位置是:

最后,你必须将这些路径更新到克隆仓库的位置。
这里还有一些设置,如下:
当前不支持,所以我把它禁用了。我也关闭了警告,否则在你编译应用程序时,你会遇到很多问题(你仍然将会收到几个Value Issue 警告,当然你也可以禁用这些警告,但我很喜欢这些警告信息)。
一旦你对其它链接器标志(Other Flags)和标题搜索路径( Paths)做出更改后,你就可以建立并运行这个应用程序了。
很好,现在你已经有一个使用了的iOS 应用程序!让我看看看它是怎样工作的。
使用C++ API
iOS 上的是用C++编写的,但是你需要编写的C++代码的程序是非常有限的!这一点你很幸运。通常你将执行以下一些操作:
1. 加载.pb 文件中的权重和图;
2. 使用图时先启动会话;
3. 将你的输入数据放入输入张量;
4. 在一个或多个结点上运行计算图;
5 得到输出结点的输出张量值,
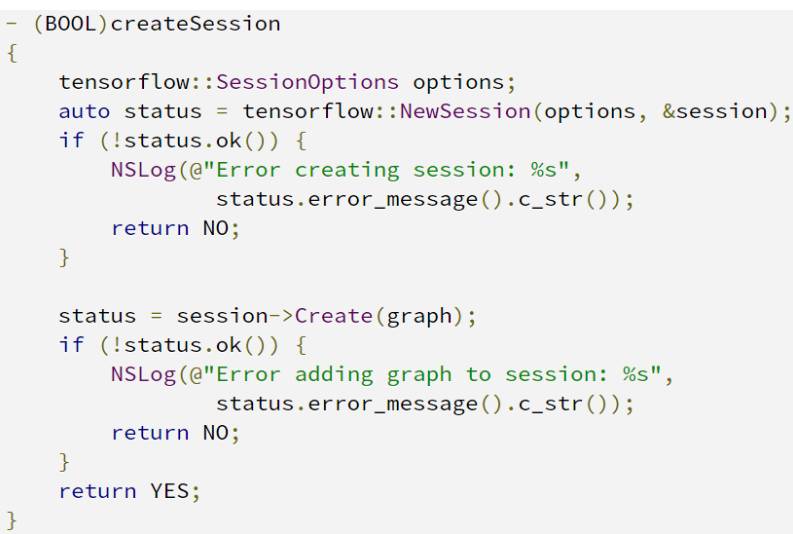
在这个演示的应用程序中,这一切都在.mm 文件中完成。首先,让我们加载计算图:

Xcode 项目包括了.pb 图,它是由我们在graph.pb 上运行和ce 得到的。如果你试图加载graph.pb,你将得到一些错误信息:

该C++ API 支持的操作比API 支持的操作少。在这里,在我们损失函数结点的操作在iOS 上是不可用的。这就是为什么我们使用来简化我们的图的原因。在加载图后,我们开始启动会话:
一旦我们启动了会话,我们就能够利用它做一些预测。预测:将包含20 个浮点数的数组作为作为声学特征传入计算图。
让我们看看该方法是怎样工作的:

首先,我们定义输入数据张量x,该张量的形状为{1,20},即1 个样例,20 个特征。然后将我们的数据从数组转换成中的张量。
接下来,我们运行会话:
使用如下类似中的代码,看看发生了什么:
这条命令并不那么简洁,我们创建了,结点矢量,以及保存结果的一个矢量。最后,我们告诉会话来做我们想做的事情。
一旦启动会话,运行了结点,我们就能打印出结果:

出于我们的目的,仅仅运行到结点就足够了,但是我也想看看预测的准确率,所以我们也运行了结点。
运行应用程序
你可以在模拟器或其它设备上运行该应用程序。在模拟器上,你可能会再次接到「The wasn't to use SSE4.1 」的消息,但是在设备上,你不应该会接收到这些消息。
仅仅用于测试的目的,该应用程序将仅仅做出两类预测:预测男性或女性。我们可以仅仅从测试集中随机取出相应的数据来做预测。
运行该应用程序,你应该看到以下输出。该应用程序首先打印出图中的节点:

注意:此图仅仅包括了进行预测所需的操作,并没有给出训练信息。然后打印预测结果:

如果你在脚本中尝试相同的样例,你将得到完全相同的答案。我们的任务终于完成了!
注意:对于这个演示项目,我们使用的数据仅仅是从测试集中抽取出来。如果你想使用该模型去处理实际音频,那么你需要将音频转换成20 种声学特征。
iOS 行的优点和缺点
是一款强大的用于训练机器学习模型和实现新算法的框架。为了训练大模型,你甚至可以在云端使用。
本文除了讲述如何训练模型外,还展示了如何将添加到你的iOS 应用程序中。在本节中,我想总结一下这样做的优点与缺点。
iOS 上使用的优点:
iOS 上的不足:
个人认为,我现在不提倡在iOS 上使用。目前优点还不足以战胜缺点,但作为一款年轻的产品,谁知道它未来会怎样呢?
注意:如果你决定在你的iOS 应用程序中使用,你应该意识到人们很容易从你的应用程序包中复制计算图的.pb 文件,这很不安全。但这个问题并不是中所特有的,由于冻结图文件( graph file)包含了你的模型参数和计算图定义,因此你可以由此进行逆向工程。如果你的模型相当具有竞争力,你可能需要找出某种方式避免它被剽窃。
使用Metal,在GPU 上训练模型
在iOS 应用程序中使用的一个缺点是不能使用GPU。对于特定的项目,可能模型和数据都较小, 可能满足我们的需求。然而,对于更大的模型,尤其是深度学习,你可能最好使用GPU。在iOS 上,就意味着使用Metal。
你仍然可以在你的Mac 上利用训练模型,对于大模型你可以使用GPU 甚至在云端训练,但在iOS 上运行的推理代码使用了Metal,而不是库。
训练好之后,我们需要导出我们学习到的参数W 和b,将其转换成Metal 能够读取的某种格式。幸运的是,我们可以将它们保存为二进制格式的浮点数列表。
再花时间写一个脚本.py;它与test.py 文件很相似,用于加载计算图的定义和检查点()。使用如下代码:
W.eval() 用于计算当前的W 值,并以NumPy 数组返回(这与sess.run(W) 所做的事情一样)。然后,我们使用() 将Numpy 数组保存为二进制文件,这就是我们需要做的事情。
注:对于我们简单的分类器,W 是一个20 x 1 的矩阵,它仅包括了20 个浮点数。对于更加复杂的模型,你模型的参数可能会是一个4D 的张量。这种情况下,你将不得不对其中的一些维度做变换,因为中的数据存储形式与Metal 的数据存储形式不一样。这可以通过简单的tf.() 命令来实现,但是这对于我们的分类器而言是不需要的。
让我们看看我们回归的Metal 版本。你可以在源代码的文件夹中找到这个Xcode 项目,它是用Swift 语言写的。
回归使用了如下公式计算:
这个公式与神经网络中的全连接层中所用的公式一样,所以要用Metal 实现我们的分类器,我们仅仅需要使用层。

首先我们将W.bin 和b.bin 加载到Data 对象中;
然后我们创建全连接层:

由于输入是20 个数字,所以我决定使用一个全连接层来处理有20 个通道的维度为1 x 1 的「图片」。预测结果是一个数值,所以全连接层仅使用一个输出通道。
输入和输出数据被储存在(与它们维度相同的) 对象中。

与应用程序的版本一样:对于每个样本,预测方法以20 个浮点数输入。这是完整的方法定义:
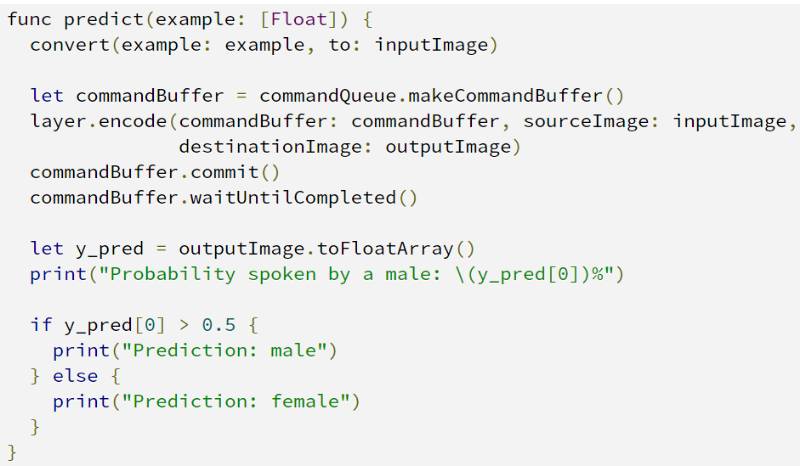
这是运行会话的Metal 版本,(:to:) 和() 方法是加载数据和输出对象的帮助器。 f
这就是Metal 应用程序!您需要在设备上运行此应用程序,因为模拟器上不支持。运行时,它应该输出以下内容:

注:这些概率与使用预测的概率不完全相同,因为Metal 使用的是16 位浮点数,但是最终结果很接近。


扫码关注,更多惊喜


 在线咨询
在线咨询 